
To Be Serverless

Alright to be serverless, just pick from AWS' list here and call it good. Next blog post.
Well, okay, there's more to it and a recent discussion with the wonderful David Norton (of Platformers) and the insightful Seth Doty triggered a line of thinking. What does it truly mean to be "serverless"?
Within the scope of this post, I will keep it limited to AWS services though many places offer similar serverless options as well.
Serverless, Easy Mode
Having worked with a few clients, one of the easiest and most common ways to move to a serverless architecture is to take existing APIs and move them to a combination of API Gateway and Lambdas. At it's core, you basically have an API endpoint that triggers one or more lambdas.
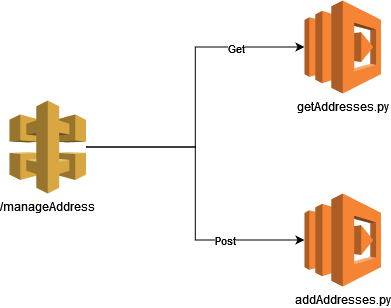
Now these lambdas can do a number of things, such as talk to databases, run script, plug into other AWS services, and so forth. However, a lambda is code running in the cloud that not only do engineers not touch the infrastructure it's executing on, but can't - they can provide parameters, but they aren't spinning up Compute instances to run them. All of that is abstracted by AWS and thus makes it "serverless" - you simply don't do anything with servers. API gateway is the same, it's not ran on a specific EC2 instance, but rather managed behind the scenes by AWS.
This makes it pretty easy to see - not only can you not manage the servers, you don't have to at all. Serverless, easy peasy.
Serverless, Hard Mode
So, Seth, David, and I all had a discussion about an edge case of serverless. There is a concept of Fargate where you can run containers or Kubernetes on Fargate and not manage servers at all. Having wrangled a lot of Kubernetes servers, this is a breath of fresh air (though there are some distinct caveats to using it for EKS that won't be discussed in this blog post). Regardless, you give ECS (for containers) or EKS (for Kubernetes) some light parameters and AWS manages all the servers. Need a bigger runtime for your container? AWS scales it for you. Is it a different node? A spot instance? How many EC2 instances are powering it? You don't know and certainly don't care - it just works.
But let's talk about those containers a moment.
If I write a little container that deploys on ECS on Fargate, is it serverless? It most certainly doesn't run on a server I manage and Fargate is listed as a serverless AWS product. I could deploy a small fleet of containers on ECS on Fargate and I still don't manage those servers. I pay for raw usage, but AWS is still the one managing the actual server.
However, I could, in turn, take those containers and run them locally using something like docker-compose or I could go over to another provider, such as DigitalOcean and throw these containers on Droplets. In this case, I'd be managing the server, whether locally or a cloud-based server. In this, are we serverless?
The difference between running three containers on Fargate and running three containers on EC2 (through ECS) is who is managing the Compute power. My little diagram below shows the difference between serverless (on the left) and not serverless (on the right). In the not serverless version, I would be deciding on sizes of the EC2 instances and manging when they break or need to scale.
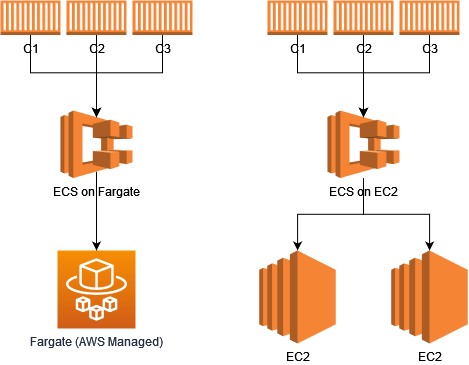
However, I could take this show on the road and do this myself elsewhere. In fact, I could take it to another provider, such as Google and run it with their Kubernetes offering on their Compute services or even run it on different Raspberry Pis (which I would personally connect through my Tailnet).
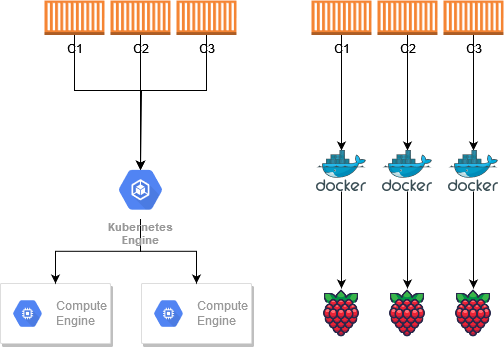
In this case, altthough you are using serverless features, such as Fargate, you aren't truly serverless. You are chosing to not use a server, or rather let AWS do all the server magic, but you can still use a server. The line here is definitely not can you remove the server but rather can you even touch the server and recreate it.
In conclusion
Serverless is more than when you can remove the server part of your processing, but more of when you cannot access it at all. When it is completely abstracted and untouchable is when you are truly serverless.
David, Seth, and I didn't come away exactly agreeing on all points, but it's safe to say that the discussion was spirited and in-depth. I hope this definition helps clarify the demarcation of chosing to have someone else manage the server and being truly serverless. As always, I take thoughts on how I might be wrong or how you'd clarify this point.
Again, thanks to Seth Doty and David Norton for the discussion!



